Note: GMail misclassified my last newsletter as spam for many readers. ¯\_(ツ)_/¯ If you missed it, you can read it and all past issues at https://kevinlynagh.com/newsletter/.
Upcoming travel
Let me know if you want to grab a coffee in any of these places!
- Sept 1–3: Bilbao, Spain
- Sept 17–20: Leuven, Belgium (for Heart of Clojure)
- Sept 20–23: Budapest, Hungary
- Sept 24–28: Montreal, Canada
- Sept 29–Oct 5: New York, USA (maybe Boston too?)
Robotic inventory management
A friend of mine has developed a robotic system for accurately dispensing exact quantities of small, loose parts (nuts, bolts, screws, etc.). He recently asked for my advice on how to set up an online shop: In particular, he wants online orders to automatically trigger his system (send CAN bus messages to print labeled bags, drop them onto conveyor belts, dispense parts, etc.) so that all he has to do is hand over the bags to the delivery service.
While this is quite a well-trodden problem space, I’m chagrined that there aren’t any solutions I feel great about.
Shopify seems like an obvious choice, but my initial few hours of exploration surfaced several impedance mismatches:
- It’s not clear how to model his products, which vary along several dimensions (standard, size, length, color, etc.) and would hit Shopify’s option/variant limits.
- Given this variation and his market, he needs a custom storefront (something like McMaster-Carr, one of the best-designed online stores); I’m sure this is possible in Shopify, but it’s not clear to me how easy it is compared to, e.g., going fully DIY.
- For managing the inventory, it’s not clear if Shopify is capable of being the “source of truth”, as there are a ton of “internal” concerns to be tracked:
- Physical inventory may be scattered across multiple locations around his warehouse, on-order from suppliers, loaded into specific dispensing units, etc.
- The system state includes details like bags on conveyor belts and dispensing machine status, which I suspect aren’t representable in Shopify’s data model (plus it’d kill me inside if advancing a European conveyor belt would requires a dozen API roundtrips to Canada).
- Another friend specifically said Shopify was too limited for his electronics manufacturing and he had to switch to PartsBox.
- Two people I asked said Shopify aggressively changes/deprecates their API, and for them dealing with those changes distracted from their core business.
On the other hand, it’s not clear to me how to build this system without having to tackle a bunch of incidental complexity. Even assuming we use Shopify (or another service — open to suggestions) as a frontend for payments, collecting shipping addresses, etc., that still leaves the inventory management and robotic fulfillment system.
Conceptually the system design is straightforward:
- We have webhooks or poll Shopify every 5 minutes for new orders
- Those orders (maybe better modeled as “fulfillment jobs”?) are added to some queue
- Another service looks at that queue, gets the jobs it can fulfill based on current inventory, and kicks off the machines.
From a modeling perspective I’m confident I can use something like Rust’s Algebraic Data Types to make nice lil’ state machines for the business domain. However, there’s tons of complexity around incidental, boring stuff:
- The queues should be durable in case of, e.g., power outages.
- The queues should be visible via some basic user interface (e.g., basic HTML tables) so operators can understand why a machine is/isn’t doing something, what’ll happen next, etc.
- The system should keep history — when did an order come in, when were items successfully picked, when did operators pause/cancel jobs, etc.
- It should be hard to accidentally delete everything.
All of these are solved problems in the large, when you’re on EC2 and have an army of developers to write serialization/deserialization plumbing, implement data migrations, and operate your Kafka clusters or whatever.
But how can this sort of system be built in the small? What’s the best solution for a one-person operation selling (at most) a few hundred orders of maybe a few hundred components a day? That’s just megabytes of data, and (in theory) a single computer should be more than sufficient.
But in practice, what are the options? Duct-taping Shopify together with Google Sheets / Airtable / Retool?
I’m curious about how y'all would solve the more general systems/information management problem here.
Like a moth to a flame, I’m tempted to try hand-rolling some kind of Rust framework built on top of durable queues with web UI and schema migration. But before I do, I’m curious to hear about what y'all might try. Open-source frameworks? Commercial apps? Abandonware from the 90’s? I’m all ears!
I find LLMs useful
My friends seem divided into two groups: Those extremely excited about LLMs and using them daily, and those who’re skeptical and/or who’ve bounced off ‘em. I spent most of 2023 in the latter group, but after seeing enough specific examples of people solving their problems with LLMs I kept trying to use 'em and have now had enough successes that I’m firmly in the “yeah, these are great” category.
I shared a few of my discussions with GPT-4 back in February, and this time I want to shout out the Cursor IDE. It’s a fork of VS Code that has a few specific UX iterations that make it easier to interface with LLMs:
- select specific program text and ask a question about it and/or request it be refactored
- LLM suggestions are returned as a diff, and you can accept/reject specific hunks
- use an
@-notation (like twitter) to include specific files or documentation (which Cursor can index from any URL) in the context window with your query
Being able to say, e.g., “Use only types and methods in @stm32f103c8” is extremely helpful for generating good output with the Rust Embassy framework, as it relies on chip-specific code generated at build-time from macros and build.rs scripts.
I find LLMs shine when writing Rust, as:
- there can be a ton of boilerplate around type declarations (especially when using Embedded Rust and that community’s love of safety-via-type-system)
- the Rust compiler will call the LLM out for imagining non-existent methods, and the compiler’s specific error messages can be a sufficient prompt for the LLM to fix its own mistakes.
Most of the benefit I’ve gotten from LLMs hasn’t been skill-enhancement but motivational — they help me emotionally overcome the dread/boredom of fighting with the Nth UI library of my career or writing out Arc::new(Mutex::new(...)) for the thousandth time.
In situations where previously I would’ve just not coded anything at all, now I’m more inclined to try coaching an LLM for 5 minutes, which sometimes yields cool results.
For example, I was streaming a voltage signal from an embedded platform to my computer via USB, where I was just printing the numbers to stdout. I realized it’d be nice to have a live oscilloscope-type view, but it wasn’t something I wanted to sink an hour into. I copy/pasted my print-USB-to-stdout to a new file, then asked Claude (via Cursor) to convert the code into a a graphical app displaying a line chart using the egui Rust framework.
It generated a page of code, but that failed to compile because the egui folks had factored their line chart out into a separate crate. So I indexed that crate’s documentation and said “Please refactor to use the new egui_plot crate as documented @here”, Claude fixed the errors, and I had a running plot up in about 5 minutes.
I noticed the plot wasn’t updating as fast as the stdout streaming had been, and realized that the version Claude generated only polled for new data on every frame (60 Hz) rather than at the full rate allowed by USB (1000 Hz). I said:
Extract the USB reading into a separate thread so that we always read the USB as fast as possible, regardless of how often the app update function is called.
I’ll spare you the diff, but Claude did pretty much what I asked. Here’s a snippet of its response:
Here’s a brief explanation of the changes:
- We’ve introduced
Arc<Mutex<>>to safely share the samples between threads.- A new
usb_reading_threadfunction has been created to continuously read from the USB device.- The main function now spawns this thread before starting the GUI.
- The
ADCAppstruct now only contains the shared samples.- The update method of
ADCAppno longer handles USB reading; it just displays the data.These changes ensure that USB reading occurs continuously in a separate thread, while the GUI updates independently at its own rate.
Again, not a skill issue — all of this makes sense to me and is pretty much how I would’ve done it. I didn’t have the energy to eat this low-level programming garbage, but I had the energy to supervise an LLM which turned it around in literally 10 seconds.
Nicholas Carlini has a ton more examples.
Health/exercise follow-ups
After the last newsletter, one reader recommended SiPhoX Health, a $165/quarter bloodwork-by-mail service for measuring biomarkers like ApoB, Vitamin D, HDL/LDL/total cholesterol. Sounds like it may be cheaper (and definitely more convenient) than dropping into a Labcorp for a blood draw.
A few other folks wrote in to add on the “saving for later” theme, recommending:
- flossing daily (I love this Xlent woven, which is the style you want to actually clean effectively. A dental hygienist once put it succinctly: “Avoid Glide floss — it’ll just glides over the plaque on your teeth and doesn’t do shit.”)
- annual teeth cleaning (I always insist on them giving me copies of my chart and X-rays after my visit — very handy to have this if you move countries (dentists) frequently…)
- wearing sunscreen (I use this Altruist stuff at home and a < 100mL when traveling)
- moisturizing in the morning, after washing your face, and before bed. (I just discovered my partner does this, but failed to mention it to me in the past 10 years (╯°□°)╯︵ ┻━┻ So let me be your friend and tell you now: Just put one of these CeraVe lotion dispensers next to your toothbrush and keep a tiny 25mL jar of this Nivea Cream for your daily carry, and you’ll look less like a raisin when you’re older.)
Yes, all good ideas, highly recommended!
As for my fitness routine:
I’ve been running 3x weekly for 90 minutes. While I haven’t bothered with a heart-rate monitor yet, I suspect I’m closer to Zone-2 training since I swapped out my fast-paced Justice and Robyn-filled iPod shuffle for podcasts. (I’m just carrying my iPhone in an old hydration backpack and using these $25 wireless earbuds, which work about 90% as well as my literally-10x-the-price Sony earbuds.)
- I thought it’d be fun to try “barefoot” minimal shoes; after reading mixed Reddit comments about the durability of Vivo shoes, I just picked up these €16 Geweo shoes on Amazon and they have been working great.
I’ve also been going 2x weekly for 60 minutes to a generic we-have-machines-and-dumbbells gym, following this minimalist workout plan. I’m only a few weeks in, but it’s nice to have regular resistance training and progressing weights again.
Exercising five times a week is the most frequent routine I’ve ever done, and so far it feels great — underscoring that, at least for me, not exercising is what makes me tired.
Casual statistical modeling + learning NumPy
I’ve never formally studied statistics, so at a friend’s recommendation I’ve been working through McElreath’s Statistical Rethinking with his 2023 online lectures. (Don’t skip the latter — McElreath has a great sense of humor.)
The book and lectures do a great job walking through examples of building casual graphs to precisely define your model of interactions between variables and justify why you do or do not “control” for some of those factors. There are both fun examples (“does Waffle House cause divorce?”) and ones relevant to topics in the social/pop-science discourse (“do people get happier as they get older?”).
The overall approach taught in the book is to:
- Write down (on paper) a casual graph.
- Write down (in code) a generative model — i.e., something that, given a set of parameters, can produce “observation” samples.
- Use your actual observations (and Markov Chain Monte Carlo) to find the parameter distributions that are consistent with your observations.
- Use these distributions (and the uncertainty inherent within them) to make decisions about your specific situation.
This appeals to me as a broadly useful, general approach — rather than shop around for some closed-form “test” that has a bunch of assumptions baked into it, I can just write some code and throw compute at my problem.
I’ve also been skimming Pearl’s Causal Inference in Statistics, which prompted me to have a go at generating Simpson’s Paradox using Z3.
While going through Statistical Rethinking, I’ve been using this Python/Numpyro code translation rather than the book’s R. Although I spent a year writing R in my first job out of college and haven’t found a better exploratory data visualization tool than ggplot2, I figured that a casual data scientist like myself would be better served staying within the more popular NumPy / Pandas ecosystem.
For Python broadly:
- I couldn’t find a nice way to setup Emacs with Python, so I just use VS Code’s built-in Jupyter Notebook environment.
- Rye is the first Python management thing that I’ve gotten to do what what I want: specify and lock dependency and Python versions on a per-project basis.
For learning NumPy:
- This lecture provides a great conceptual overview.
- From Python to NumPy explains the internal memory representation and has some complex usage examples.
- This visual guide is fun.
- Make sure you memorize/understanding the shape compatibility (“broadcasting”) rules.
- The numpy-100 exercises with solutions combined with Anki is a good way to force yourself to load the basics into your brain.
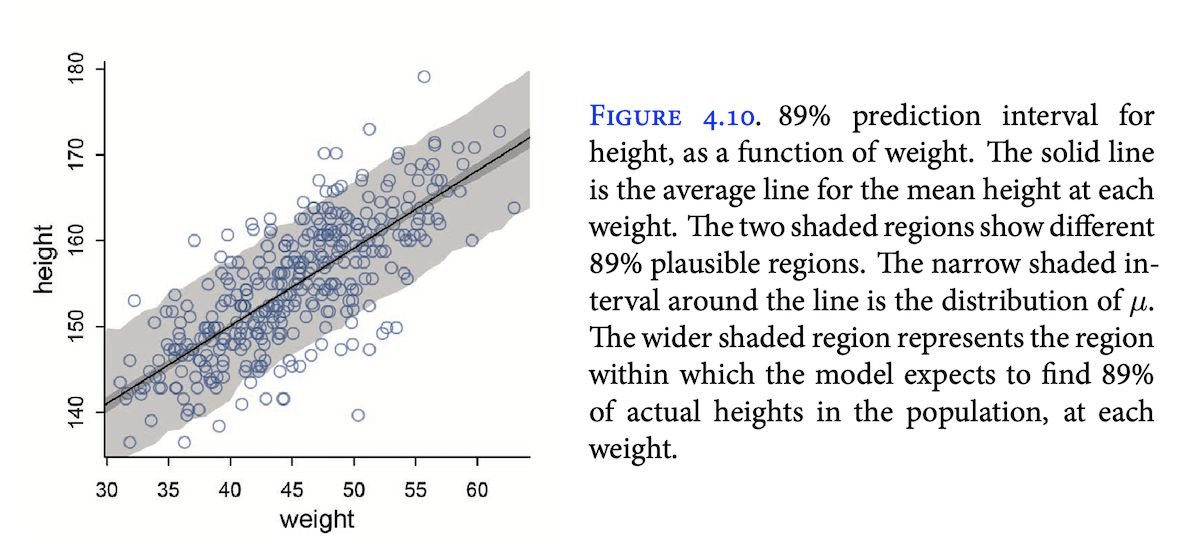
I haven’t found a plotting library that I like. Plotly feels OK, but the recommended “Plotly Express” API doesn’t make it easy to, e.g., combine points and lines on the same chart — it’s doable, but you’ve got to break out into a sort of mutable and verbose API. I tried Altair for 5 minutes, but quickly ran into rendering issues because it was trying to dynamically load JavaScript from the web after I’d already installed the Python package (no thanks!) I’ll probably try PlotNine, a Python ggplot clone, next, but I’m open to any suggestions for a Python library which can make, e.g., a scatterplot with a fit curve and shaded area indicating a compatibility interval. E.g., this figure from the book:
Haunted stm32f103
I’m helping a friend write firmware for an stm32f103 (the famous “blue pill” microprocessor). The requirements are pretty straightforward:
- use timer-driven DMA to copy static bytes from flash to GPIO (pulse density modulation to generate an analog signal)
- read ADC values as fast as possible (again, with DMA)
- send those ADC values to a host PC over USB
I gave it a shot using the Rust Embassy framework, and it all works swimmingly…except that the MCU freezes and locks out the debugger within 10–60 seconds (indeterminate). Not hard fault, mind you, but all of the CPU registers end up pointing to garbage like 0x0 or 0x2100_0000.
I asked my much more experienced (literally programs embedded guidance control for rockets) friend for help. He was able to reproduce the issue, but we’re both still stumped as to the root cause:
A single register write before the WFE instruction seems to fix it. Four NOPs do not. Feels like this must be some weird bus mux contention issue involving processor sleep…but…it’s pretty wild.
You feeling lucky? Check out this repo for more details and code that reproduces the issue — all it requires is an stm32f103 (blue pill, nucleo board, etc.) and a few minutes.
Misc. stuff
Soldering wires - how to autofeed exact amounts of solder without special equipment.
Internet Shaquille On Making $250K/ yr without selling out. My favorite cooking YouTuber on creator norms, how he got started, and the infinite number of opinions.
“Something is pumping out large amounts of oxygen at the bottom of the Pacific Ocean, at depths where a total lack of sunlight makes photosynthesis impossible.”
A Shaper3d founder’s CAD deep dive tweets. See also their Manufacturing Spaces podcast interview.
The Business (and Social Good) of Destroying Old Air Conditioners
“Real Madrid’s stadium is undergoing renovation work and one of the new additions to the iconic stadium is a state-of-the-art pitch retraction system.”
“The same woman’s DNA was found at 40 crime scenes, eventually leading to her identification by police, but she was never punished. Why?”
“In railway and rapid transit parlance, the Spanish solution is a station layout with two railway platforms, one on each side of the track, which allows for separate platforms for boarding and alighting.”
Making of Super Automatic Espresso Machines: Eversys Factory Tour in Switzerland. These machines are used by Blank Street Coffee in a strategy to let baristas spend more time chatting up customers. (TIL Blank Street is venture-backed; that explains why I saw them all over London when I lived there.)
Commentary on the shoe that won the World championships of shoemaking 2024
Inside the tiny chip that powers Montreal subway tickets “I found that the best way to move the chip between processing and a microscope slide was to put the chip in a few drops of water and move it with a pipette. Even so, there were a couple of times that I lost track of the chip and had to check some specks under the microscope to determine which was the chip and which were dirt.”
Beyond Steel Tanks: GLP-1 drugs could one day outsell iPhones, but there is not enough biomanufacturing capacity to make them. For solutions, we should look away from the factory.
A Modest Proposal For Republicans: Use The Word “Class” (2021)
Inside USA Cricket’s Incredibly Unlikely, Maximally Joyful World Cup Run
HouseGPT: “And then GPT became my co-pilot. Here’s my guide on how I used it to uncover connections my doctors missed and navigate my rare diseases.”
Everything You Need to Know About Napoleon Bonaparte – Matt Lakeman
“Okay, time for a DFM roast so all you engineers can see how machinists think.”