Hi friends,
I’ll be attending Babashka Conf on May 8 and Dutch Clojure Days on May 9. If you’re attending either (or just visiting Amsterdam), drop me a line!
On sabotaging projects by overthinking
When I have an idea for a project, it tends to go in one of these two directions:
I just do it. Maybe I make a few minor revisions, but often it turns out exactly how I’d imagined and I’m happy.
I think, “I should look for prior art”. There’s a lot of prior art, dealing with a much broader scope than I’d originally imagined. I start to wonder if I should incorporate that scope. Or perhaps try to build my thing on top of the existing sorta-nearby-solutions. Or maybe I should just use the popular thing. Although I could do a better job than that thing, if I put a bunch of time into it. But actually, I don’t want to maintain a big popular project, nor do I want to put that much time into this project. Uh oh, now I’ve spent a bunch of time, having neither addressed the original issue nor experienced the joy of creating something.
I prefer the first outcome, and I think the pivotal factor is how well I’ve internalized my own success criteria.
For example, last weekend I hosted my friend Marcin and we decided it’d be fun to do some woodworking, so we threw together this shelf and 3d-printed hangers for my kitchen:

Absolute banger of a project:
- brainstormed the design over coffee
- did a few 3d-print iterations for the Ikea bin hangers (OnShape CAD, if you want to print your own)
- used material leftover from my workbench
- rounded the corner by eye with a palm sander
- sealed the raw plywood edge with some leftover paint from a friend
- done in a weekend
The main success criteria was to jam on woodworking with a friend, and that helped me not overthink the object-level success criteria: Just make a shelf for my exact kitchen!
In contrast, this past Friday I noticed difftastic did a poor job, so I decided to shop around for structural/semantic diff tools and related workflows (a topic I’ve never studied, that I’m increasingly interested in as I’m reviewing more and more LLM-generated code).
I spent 4 hours over the weekend researching existing tools (see my notes below), going through dark periods of both “semantic tree diffing is a PhD-level complex problem” and “why do all of these have MCP servers? I don’t want an MCP server”, before I came to my senses and remembered my original success criteria: I just want a nicer diffing workflow for myself in Emacs, I should just build it myself — should take about 4 hours.
I’m cautiously optimistic that, having had this realization and committing myself to a minimal scope, I’ll be able to knock out a prototype before running out of motivation.
However, other long-running interests of mine:
- interfaces for prototyping hardware (discussed September 2023)
- a programming language that fuses what I like about Clojure and Rust (November 2023)
- a programming language for CAD (constraints, bidirectional editing, other dubious ideas)
seem to be deep in the well of outcome #2.
That is, I’ve spent hundreds of hours on background research and little prototypes, but haven’t yet synthesized anything that addresses the original motivating issue.
It’s not quite that I regret that time — I do love learning by reading — but I have a nagging sense of unease that my inner critic (fear of failure?) is silencing my generative tendencies, keeping me from the much more enjoyable (and productive!) learning by doing.
I think in these cases the success criteria has been much fuzzier: Am I trying to replace my own usage of Rust/Clojure? Only for some subset of problems? Or is it that I actually just need a playground to learn about language design/implementation, and it’s fine if I don’t end up using it?
Ditto for CAD: Am I trying to replace my commercial CAD tool in favor of my own? Only for some subset of simple or particularly parametric parts? Do I care if it’s useful for others? Does my tool need to be legibly different from existing open-source tools?
It’s worth considering these questions, sure. But at the end of the day, I’d much rather have done a lot than have only considered a lot.
So I’m trying to embrace my inner clueless 20-year-old and just do things — even if some turn out to be “obviously bad” in hindsight, I’ll still be coming out ahead on net =D
Conservation of scope creep
Of course, there’s only so much time to “just do things”, and there’s a balance to be had. I’m not sure how many times I’ll re-learn YAGNI (“you ain’t gonna need it”) in my career, but I was reminded of it again after writing a bunch of code with an LLM agent, then eventually coming to my senses and throwing it all out.
I wanted a Finda-style filesystem-wide fuzzy path search for Emacs. Since I’ve built (by hand, typing the code myself!) this exact functionality before (walk filesystem to collect paths, index them by trigram, do fast fuzzy queries via bitmap intersections), I figured it’d only take a few hours to supervise an LLM to write all the code.
I started with a “plan mode” chat, and the LLM suggested a library, Nucleo, which turned up since I wrote Finda (10 years ago, eek!).
I read through it, found it quite well-designed and documented, and decided to use it so I’d get its smart case and Unicode normalization functionality.
(E.g., query foo matches Foo and foo, whereas query Foo won’t match foo; similarly for cafe and café.)
Finding a great library wasn’t the problem, the problem was that Nucleo also supported some extra functionality: anchors (^foo only matches at the beginning of a line).
This got me thinking about what that might mean in a corpus that consists entirely of file paths.
Anchoring to the beginning of a line isn’t useful (everything starts with /), so I decided to try and interpret the anchors with respect to the path segments.
E.g., ^foo would match /root/foobar/ but not /root/barfoo/.
But to do this efficiently, the index needs to keep track of segment boundaries so that the query can be checked against each segment quickly.
But then we also need to handle a slash occurring in an anchored query (e.g., ^foo/bar) since that wouldn’t get matched when only looking at segments individually (root, foo, bar, and baz of a matching path /root/foo/bar/baz/).
Working through this took several hours: first throwing around design ideas with an LLM, having it write code to wrap Nucleo’s types, then realizing its code was bloated and didn’t spark joy, so finally writing my own (smaller) wrapper.
Then, after a break, I realized:
- I can’t think of a situation where I’d ever wished Finda had anchor functionality
- In a corpus of paths, I can anchor by just adding
/to the start or end of a query (this works for everything except anchoring to the end of a filename).
So I tossed all of the anchoring code.
I’m pretty sure I still came out ahead compared to if I’d tried to write everything myself sans LLM or discussion with others, but I’m not certain.
Perhaps there’s some kind of conservation law here: Any increases in programming speed will be offset by a corresponding increase in unnecessary features, rabbit holes, and diversions.
Structural diffing
Speaking of unnecessary diversions, let me tell you everything I’ve learned about structural diffing recently — if you have thoughts/feelings/references in this space, I’d love to hear about ‘em!
When we’re talking about code, a “diff” usually means a summary of the line-by-line changes between two versions of a file.
This might be rendered as a “unified” view, where changed lines are prefixed with + or - to indicate whether they’re additions or deletions.
For example:

We’ve removed coffee and added apple.
The same diff might also be rendered in a side-by-side view, which can be easier to read when there are more complex changes:

The problem with these line-by-line diffs is that they’re not aware of higher-level structure like functions, types, etc. — if some braces match up somehow between versions, they might not be shown at all, even if the braces “belong” to different functions.
There’s a wonderful tool, difftastic, which tries to address this by calculating diffs using treesitter-provided concrete syntax trees. It’s a huge improvement over line-based diffs, but unfortunately it doesn’t always do a great job matching entities between versions.
Here’s the diff that motivated this entire foray:
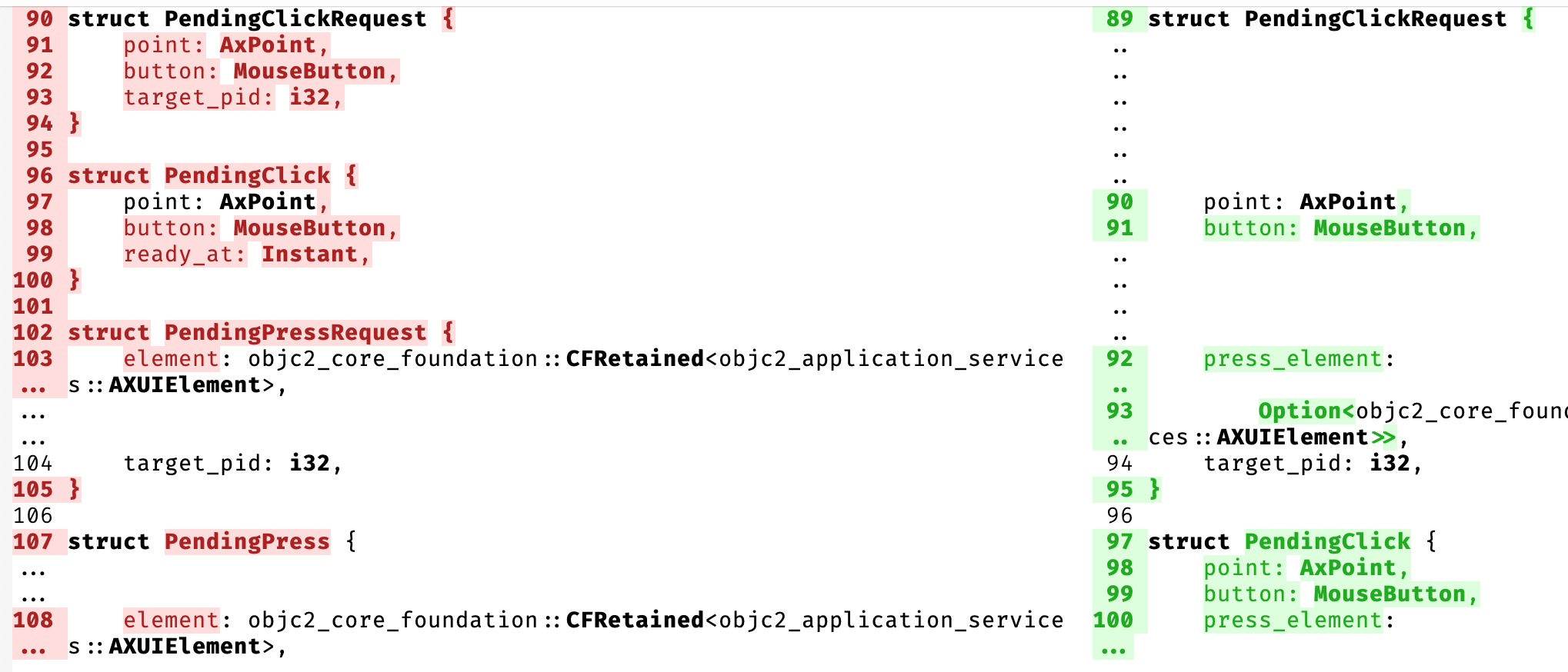
Note that it doesn’t match up struct PendingClick, it shows it deleted on the left and added on the right.
I haven’t dug into why difftastic fails to match here, but I do feel like it’s wrong — even if the overall diff would be longer, I’d still rather see PendingClickRequest and PendingClick matched up between both sides.
Here’s a summary of tools / references in the space:
The most “baked” and thoughtful semantic diff tool I found is, perhaps unsurprisingly, semanticdiff.com, a small German company with a free VSCode plugin and web app that shows diffs for github PRs. Unfortunately they don’t have any code libraries I can use as a foundation for the workflow I want.
- this semanticdiff vs. difftastic blog post covers a lot of great details (including that difftastic doesn’t even show semantically meaningful indentation changes in python !!!)
- one of the authors has great HN comments with hard-won background knowledge. E.g., they moved away from treesitter because it’s unreliable for semantics:
Context-sensitive keywords in particular were a constant source of annoyance. The grammar looks correct, but it will fail to parse because of the way the lexer works. You don’t want your tool to abort just because someone named their parameter “async”.
-
- built on treesitter, has MCP server. README includes list of similar projects.
- lots of github stars, but doesn’t seem particularly well-documented; I couldn’t find an explanation of how it works, but the difftastic wiki says it “runs longest-common-subsequence on the leaves of the tree”
-
- research / academic origin in 2014
- requires Java, so no-go for my use case of a quick tool I can use via Emacs
mergiraf: treesitter-based merge-driver written in rust
- very nice architecture overview; tool uses Gumtree algorithm
- docs and adorable illustrations indicate this project was clearly written by a thoughtful human
- semanticdiff.com author in HN comments: > GumTree is good at returning a result quickly, but there are quite a few cases where it always returned bad matches for us, no matter how many follow-up papers with improvements we tried to implement. In the end we switched over to a dijkstra based approach that tries to minimize the cost of the mapping
weave: also a treesitter-based merge-driver written in Rust
- feels a bit “HN-optimized” (flashy landing pages, lots of github stars, MCP server, etc.)
- I looked into their entity extraction crate, sem
- core diffing code is OK but pretty wordy
- greedy entity matching algorithm
- data model can’t detect intra-file moves, even though those might be significant
- includes a lot of heuristic “impact” analysis, which feels like overreaching-scope to me since it’d require much tighter language integration before I’d trust it
- ran into buggy output when running
sem diff --verbose HEAD~4; it showed lines as having changed that…didn’t change at all.
- ran into buggy output when running
- Too much 80%-done, hypothetically useful functionality for me to use as a foundation, but props for sure to the undergrad/student(?) who’s built all this in just three months.
diffast: tree edit-distance of ASTs based on an algorithm from a 2008 academic paper.
- supports “Python, Java, Verilog, Fortran, and C/C++ via dedicated parsers”
- has a nice gallery of example AST differences
- can export info in tuples for datalog
autochrome: Clojure-specific diffs based on dynamic programming
- excellent visual explanation and example walkthrough
Tristan Hume has a great article on Designing a Tree Diff Algorithm Using Dynamic Programming and A*
My primary use case is reviewing LLM output turn-by-turn — I’m very much in-the-loop, and I’m not letting my agent (or dozens of them, lol) run wild generating 10k+ lines of code at a time.
Rather, I give an agent a scoped task, then come back in a few minutes and want to see an overview of what it did and then either revise/tweak it manually in Emacs or throw the whole thing out and try again (or just write it myself).
The workflow I want, then, is to
- see a high-level overview of the diff: what entities (types/functions/methods) were added/removed/changed?
- quickly see textual diffs on an entity-by-entity basis (“expanding” parts of the above summary)
- quickly edit any changes, without having to navigate elsewhere (i.e., do it inline, rather than having to switch from “diff” to “file)
Basically, I want something like Magit’s workflow for reviewing and staging changes, but on an entity level rather than file/line level.
In light of the "minimal scope, just get your project done” lesson I’ve just re-learned for the nth time, my plan is to:
- throw together my own treesitter-based entity extraction framework (just Rust for now)
- do some simple greedy matching for now
- render the diff to the command line
Once that seems reasonable (i.e., it does a better job than difftastic did on that specific commit), I’ll:
- wire into a more interactive Magit-like Emacs workflow (maybe I can reuse Magit itself!?!)
- add support for new languages, as I need them
- potentially explore more sophisticated score-based global matching rather than simple greedy matching
Mayyybe if I’m happy with it I’ll end up releasing something. But I’m not trying to collect Github stars or HN karma, so I might just happily use it in the privacy of my own home without trying to “commercialize it”.
After all, sometimes I just want a shelf.
Misc. stuff
I’m in the market for a few square meters of Tyvek or other translucent, non-woven material suitable for building a light diffuser — let me know if you have any favorite vendors that can ship to the EU.
How They Made This - Coinbase Commercial Breakdown. Crypto is a negative-sum parasite on productive economic activity, but has the silver lining of funneling a lot of capital to weird creative folks.
The Easiest Way To Design Furniture…. Laura Kampf on getting off the computer and designing physical spaces with tape, lil’ wood sticks, and cardboard.
Hotel California - Reimagined on the Traditional Chinese Guzheng
C is not a low-level language: Your computer is not a fast PDP-11.
Loon is a Lisp. Thrilled to discover I’m not the only one who wants to mash together Clojure and Rust. The current implementation seems to have been manically vibe-coded and I quickly ran into some terrible bugs, but on the other hand it exists so I’m not going to be a hater.
Made a print in place box so I can easily hand out printed bees🐝. “Im quite content with the result, the bees fit snugly and the box opens and closes nicely”
“There isn’t a lot of reliable information out there about how to buy a gas mask, especially for the specific purpose of living under state repression. But hopefully after reading this guide you’ll feel equipped to make an educated decision.”
“This zoomable map shows every page of every issue of BYTE starting from the front cover of the first issue (top left) to the last page of the final edition (bottom right). The search bar runs RE2 regex over the full text of all 100k pages.” A lovely reminder that user-interfaces can be extremely fast and information dense.