Reltron
← Back to Kevin's homepagePublished: 2019 Feb 1Reltron is a prototype user interface for exploring relational databases. This was a collaboration with Jamie Brandon.
Background
In 2018 August Jamie and I started talking about this problem space as part of my interest in presenting relational data. We decided to explore the problem in the context of a prototype, which we collaborated on through 2018 November.
We felt that existing database GUIs were either:
too IDE-like, oriented towards power users (who are happy to write SQL by hand) and difficult to use “casually”. Example: MySQL workbench.
over-simplified “choose a single table and see it like a spreadsheet” GUIs that make it difficult/impossible to look at data relationally (i.e., join) without resorting to writing SQL queries. Example: DB Browser for SQLite.
We wanted to explore an interface that would let someone just “open up a database” and immediately explore with searches and joins without requiring that they fully internalize the schema, tables, key relationships, etc.
The rough brief was: “a query builder/viewer that is as accessible/efficient as Access/Airtable/Fieldbook, but works on top of a standard SQL database.”
We drew inspiration from:
Bakke and Karger’s “Expressive Query Construction through Direct Manipulation of Nested Relational Results” (PDF)
Crawford’s Data modeling for humans talk at CSVConf 2017.
Next steps
Both of us think Reltron could be useful for casual database viewing tasks. However, as of Jan 2019 we’re tabling the project until we have a concrete, motivating use case to inform further development.
Future functionality / direction might include:
- Aggregation (see Bakke and Karger’s paper for more on this)
- Spreadsheet-like computation
- Editing
- Redshift / “data warehouse” queries + rough reporting
Notes
Join discoverability: When one encounters a new database, it’s hard to know what tables exist and what columns can be reasonably joined to what. Reltron infers join possibilities using declared foreign-key relationships.
Initially we suggested joins within a contextual menu on the table header:
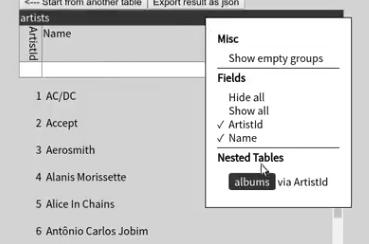
but during user testing few people actually discovered and used the join functionality. (Perhaps unsurprising, since the buttons weren’t visible until you opened up the appropriate context menu.)
We tried highlighting foreign key columns:
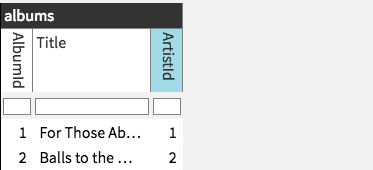
such that double clicking on the column would “expand it” in place as a join:
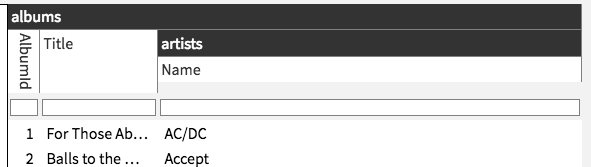
but this method only works in one direction (on tables that reference others, not on tables that are referenced by others).
We realized we could make joins more discoverable and handle both directions uniformly by showing join suggestions in an always-visible sidebar:
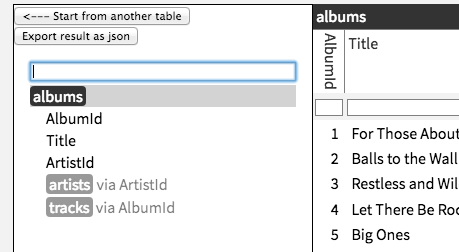
The sidebar also let us implement search and jump-to-column hotkeys that addressed frustrations we had with early prototypes, which required excessive mousing, scrolling, and context menuing.
Arbitrary search: It’d be nice if the sidebar searched all tables/columns, rather than just the visible ones. Then one could open up a new database and just start typing for what you’re looking for (“country”, “customer”, etc.) without having to know the specific table name such data might be stored within.
Join types / terminology: When joining a new table “under” a parent table, the join can be either:
- left join: parent rows shown, even if no results in sub-table
- inner join: parent rows hidden if no results in sub-table
We tried the label “show empty groups”, but I found this confusing since it appeared in the context of the child table but referred to the rows of the parent table. “Inner” and “Left” are clearer to me, but I’ve already internalized SQL semantics; unclear whether clearer language exists.
We also weren’t sure if “cycles” should be allowed in joins. E.g., starting from the “Artists” table, joining “Albums”, and then underneath that joining back to “Artists”. When Reltron showed this perfectly legal suggestion, users found it confusing and thought it was a bug — even though there are queries / data models which require such joins. (E.g., multiple self joins of the “Employees” table on the “reports to” column is necessary to find someone’s “skip level” manager.)
Arbitrary joins: It’s not clear where in the UI we’d add support for arbitrary joins; could this be done in a direct manipulation fashion, or would it have to be some kind of “wizard” popup flow?
One-to-many inline entities: Airtable has a nice UI where rows that reference from other tables are shown as inline as “bubbles”. So if there’s a “projects” table that has a column that references a record from the “clients” table, then those projects will be shown as bubbles on when viewing the “clients” table:

We attempted to do something similar, but couldn’t pull it off because we couldn’t find a reasonable heuristic or control scheme for choosing which column(s) should be shown as the bubble values. (Airtable shows the “primary field”, but that’s not concept that exists within SQL.)
From a UI perspective, it’s not immediately clear what the bubbles are or where they come from — they don’t obviously map to the “rectangular” perspective of tables with rows and columns that we assumed most users would have.
So we nixed the bubble idea and decided to keep things uniform by always displaying values in cells that are clearly associated with rows/columns/tables.
Frontend / backend architecture: We started Reltron as an Electron app using ClojureScript for frontend rendering and Julia for backend database communications. However, we couldn’t find a reasonable way to compile and ship the Julia backend with the rest of the app. (Shipping all of Julia + LLVM so that Julia could JIT and runtime would have cost 100+ MB and it wasn’t clear how much work it’d take to even make that work.)
We tried to do the backend in ClojureScript using database libraries from the Node ecosystem, but ran into race conditions and their inability to support necessary features such as in-flight query cancellation (which is required to efficiently support updating the data on every keystroke of, e.g., a column filter).
Since we weren’t thrilled by the quality of the libraries we found in the Node ecosystem, we rewrote the backend in Rust and integrated with the frontend using Neon and the architecture described here.
Hidden columns: By default all of a table’s columns are shown. However, after several joins one quickly runs out of horizontal space — so we introduced the ability to hide columns. At first, we decided to show a “hidden” column as a thick line, for an accordion-like effect:

The idea was to remind users that some columns still existed, and were just visually “narrowed” to save space.
However, as we implemented additional direct manipulation features such as column resizing and reordering, it wasn’t clear how hidden columns should interact. Should it be possible to reorder a wide column by dropping it in-between a group of hidden/narrow columns? If one resizes a column to 2px, is that the same as clicking “hide column” in the menu? Can a hidden/narrow column be resized to be visible, or does it have to be “unhidden” via the context menu first?
There’s another problem with this design: Even spending just 2px per hidden column added up to a lot of wasted horizontal space when one wanted to see just a few columns on a table that might have dozens. This also looks quite awkward when tables contains no relevant data and are just used to get to relevant data, like “invoices”, “invoice_items”, and “tracks” tables are used here:
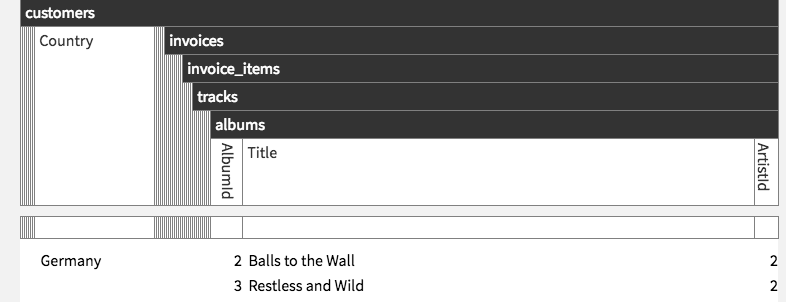
Once we implemented the sidebar (which lists all columns, hidden or not) we decided to remove the 2px reminder and hide columns outright.
Table rendering: The main data view was initially rendered using HTML <table>s, the idea being that the browser could handle all layout calculations related to hierarchical data.
However, this required us to write some awkward code to calculate rowspan / colspan attributes.
Furthermore, using tables also made it difficult to implement some of the direct manipulations such as column resizing and reordering, since the browser-computed layout couldn’t be reliably accessed from JavaScript.
So we decided to handle the fundamental width calculations ourselves and render using CSS flexbox with nested div representation.
Horizontal space: We quickly realized that horizontal space is at a premium when working with rectangular data, so Reltron saves space by sizing columns to “roughly fit” their data. When first opening/joining a table, it samples values from the backend to determine a “typical width”.
This helps most often for auto-incrementing integer ID columns, whose width grows as log10 the number of records. Here notice that the “CustomerId” label is rotated vertically to save horizontal space, and a long FirstName value in the first row is truncated.

We also considered automatically hiding synthetic key columns to save space, but decided against this since we didn’t have a clear sense of how Reltron would be used. (Defaulting to hiding ID columns might be very annoying to, e.g., a developer who is debugging log messages that reference objects by their primary key.)