Difftron
Last newsletter I wished for structural diffs in a Magit-like UI and, a few weekends later, it turned out as awesome as I’d imagined.
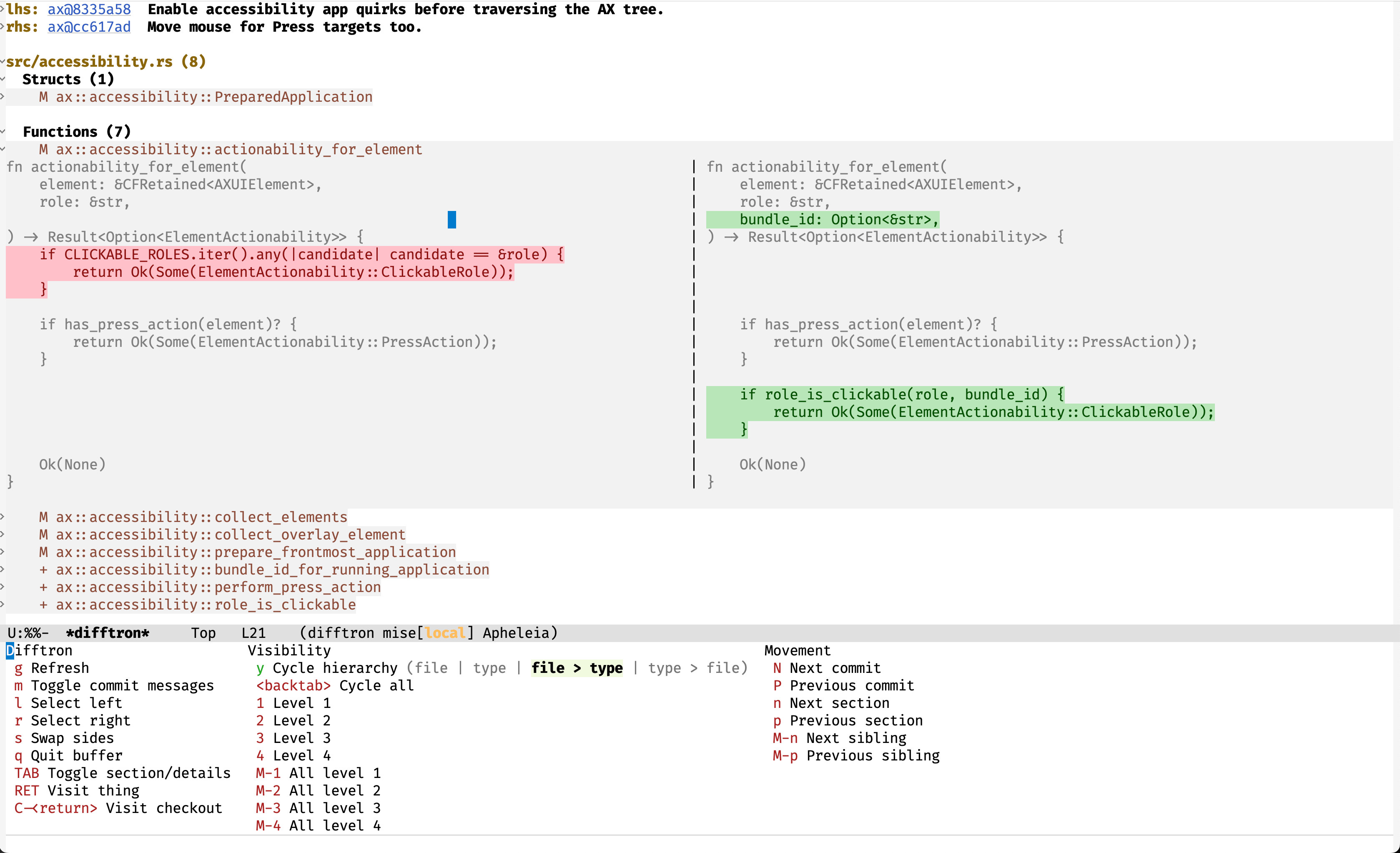
Behold, Difftron:
 15 minute demo video for more details.
15 minute demo video for more details.
Conceptually, the tool works as follows:
- A Rust binary parses code into semantic entities (functions, types, classes, etc., depending on the language)
- Entities are matched between the left and right sides of the diff based on entity type and name
- Matched entities are shown as a side-by-side diff
- Unmatched entities are marked as added/removed
This barely scratches the surface of the complex computer sciencey questions about tree diffing and heuristics for matching entities, but so far I don’t mind at all — as it turns out, just this basic scheme combined with a rich user interface already feels miles better than the standard file-and-line-based diffs I’ve been using. All of the UI credit goes to Magit and Emacs, for a few reasons:
First, Magit espouses the idea that everything can be interacted with:
Commands are invoked, not by typing them out, but by pressing short mnemonic key sequences. Many commands act on the thing the cursor is on, either by showing more detailed or alternative information about it in a separate buffer or by performing an action with side-effects on it.
In Difftron:
- the hierarchy levels can be expanded/collapsed (individually or globally) to quickly switch between “overview” and “detail” views of the diff
- the diff text itself can be used to jump to the code — to the file in the current worktree if applicable, in a buffer, or a new worktree at that ref (thus allowing one to use LSP, etc. while exploring)
- the left and right-side labels can be used to select different comparisons (press “N” or “P” to move to the next/previous commit; “enter” to pull up an autocomplete across all refs)
Second, Emacs is pretty much just text with different colors, so the default data-density is quite high. I’m sure Emacs is capable of supporting excessive amounts of whitespace to match even the most “minimal, clean, modern” (i.e., useless) web UI, but you’d have to work against the grain to mess things up.
Third, the entire system is “live”, meaning that I can imagine some new feature, prompt an LLM to implement it, and then test it without restarting Emacs.
I just defined:
(defun difftron-reload ()
(interactive)
(when (featurep 'difftron)
(unload-feature 'difftron t))
(load "/Users/dev/work/difftron/emacs/difftron.el"))
and ran it whenever I wanted to test some changes.
This made the iteration loop quite fast, which made it low-friction and fun to polish away rough edges.
All in all, it took about 8 hours over two afternoons to knock out the initial implementation in Magit and record the first demo video, then another 16 hours polishing it as I used it myself and ran it by a few friends for critique.
The entire implementation was done by Codex with GPT-5.5 High (via my $20/month ChatGPT Plus subscription), and I’ve barely touched the code myself. I mainly provided guidance in terms of:
- telling it what Rust crates to use for the language analysis (Rust Analyzer’s ra_ap_syntax for Rust; arborium for Clojure and TypeScript)
- telling it to set up dedicated scripts to lint, format, and test
- telling it to set up a minimal Emacs environment that it could use to drive the package itself and reproduce firsthand any bugs I ran into
My agents.md instructions were minimal:
- when editing Emacs code, review Magit and other package source code in /emacs/test-config/straight/repos/
- review
/scripts/for available project commands like formatting and testing- use red/green TDD workflow
- never add tests for config or script changes
Same advice I give myself, honestly: Read the source code of what you’re using, put frequent/complex tasks into scripts, and specify the success condition before trying to implement it.
On open-sourcing a vibe-coded project
Last newsletter I said:
Mayyybe if I’m happy with it I’ll end up releasing something. But I’m not trying to collect Github stars or HN karma, so I might just happily use it in the privacy of my own home without trying to “commercialize it”.
While I am indeed happy with Difftron so far, I’ve hesitated about sharing it because of a few lingering questions in the back of my mind:
- for the code, how should I distinguish between:
- code I thought hard about and wrote myself
- code I prompted and reviewed
- code I prompted and only “black box” tested
- how open am I to accepting potentially YOLO’d code from others (e.g., adding support for languages I don’t use / care about)?
- how much do I want to popularize this as a useful tool versus keep it as a playground for my own experiments?
However, all the same questions apply to the Whispertron dictation app I vibe-coded last fall, and I’m glad I released that because I’ve heard from several folks who have been enjoying it daily, which makes me happy.
Furthermore, all these concerns revolve around setting expectations, which I can simply do:
- in a project README, I can say upfront whether I intend for something to be a useful, reliable tool or a personal playground (and thus be evaluated on those merits)
- in the commit history, I can specify myself or the LLM as the author or co-author (all responsibility, of course, remains with me — it’ll just be helpful to keep track of whether some code “made sense” in a human brain or was just the result of a series of next-token predictions)
So, between that and the general principle of increasing my luck surface area, I figure I should release Difftron and any other generally useful tool I might cook up.
LLM determinism
When delegating to humans, there’s a delicate balance between:
- establishing systems and procedures to counteract our fallibility
- giving people the freedom to explore and grow (including through mistakes)
LLMs, though, can’t learn from mistakes, nor do they have creative flames that can be snuffed out by overbearing procedures, so I’m all about using them as cogs in a deterministic machine.
Contrary to the majority of GitHub repos I’ve seen lately, this cannot be done via the context window.
LLMs on their own cannot follow, for example, Graydon’s Not Rocket Science Rule of Software Engineering: “automatically maintain a repository of code that always passes all the tests”.
No matter how much you plead in markdown:
You MUST run
test.shbefore committing
there’s a chance they’ll just go ahead and commit anyway (or “fix” the failing test by deleting it, etc.).
If you want LLMs to follow a deterministic process, you must use them via a deterministic harness.
Understanding this idea is easy; the tricky part is actually building that harness.
The Not Rocket Science Rule, for example, is phrased in terms of git commits and usually implemented via a continuous integration server: Once a commit is pushed, a script attempts the merge, runs the tests, and updates the branch only if the merged code passed the tests.
This does maintain the desired invariant, but the feedback loop is long: The continuous integration failure occurs many minutes after the code change.
This wastes time, tokens, and (much worse!) potentially a full turn of human feedback (if the agent stopped before getting the CI feedback).
This article on Stripe’s coding agents puts it nicely:
We seek to “shift feedback left” when thinking about developer productivity. That means that it’s best for humans and agents if any lint step that would fail in CI is enforced in the IDE or on a git push, and presented to the engineer immediately.
So how can we change the harness to shorten the feedback loop and give agents the chance to correct their mistake?
- Running the test script after every tool call would shorten the loop, but this doesn’t seem like a great strategy — even if the testing time is negligible, the context would fill with spurious failures from testing unfinished work.
- Running the test script after the agent finishes is better, but we’d need to make sure the test script correctly handles cases like the agent organizing its work across multiple commits (I direct ‘em this way, as focused commits make for an easier-to-review history).
- Alternatively, we could run the agent without direct access to
git, instead giving it a specific “git commit tool” that always runs the tests. (Similar in spirit to a git pre-commit hook, except without the--no-verifyflag.)
I have similar implementation questions about other useful invariants beyond the Not Rocket Science Rule. E.g., how do we ensure an agent doesn’t modify the tests or write slop to the README?
- Have the harness run
git statusand discard illegal edits after every tool call? - Limit tool calls, so illegal edits cannot be made (no arbitrary bash/shell, provide an “edit” tool that refuses to work on specific files/directories)?
- Allow arbitrary bash, but only within a fine-grained Linux sandbox (UNIX user permissions?)
I’m reminded of the dichotomy between static and dynamic language strategies:
- “correct by construction”, where you only give the LLM tools that allow it to do valid operations (akin to a structural editor or typed programming language where “illegal states are unrepresentable”), versus
- letting the LLM do whatever, with the harness “raising exceptions at runtime” to prevent invariant violations
For example, if we want an LLM to rename a bunch of methods/types/variables under the invariant “don’t change the program behavior”, we could:
- follow the former strategy: only give the agent access to an LSP server’s deterministic “rename” tools
- follow the latter strategy: give the agent a shell to execute any commands, then test the invariant afterwards (by, e.g., comparing the abstract syntax trees sans identifier names)
When I’m programming, I’ll switch between these strategies depending on the specific problem and my mood. For agents, it’s not obvious to me whether one of these strategies in general dominates the other.
In terms of my work as an implementer/specifier, it’s probably easier for me to define invariants via runtime tests than by designing a set of “safe” tools:
- writing a runtime
assertis easier than designing a type system / algebra - agent harnesses already come with a bunch of generic tools
- the underlying models have been trained on their tools, so even if you did define great custom ones, the models might be less effective at using them compared to their favorite bash commands.
Ultimately which strategy to pursue is an empirical question about balancing the setup hassle (for me) with the combined performance of the model and harness.
My interest in invariants is, I hope, not some midwit folly (dimwit and genius: “Just ask the model for what you want”).
Nor does it stem from the religious purity / “safety” mindset that afflicts certain programmers. (You know, the ones whose aesthetic appreciation of category theory-inspired, borrow-checked phantom types has them constructing complex defenses against technically-possible-but-rare-in-practice “problems”.)
Rather, I’m stubbornly attached to the idea of understanding what I’m building. Having more constraints — immutable data, pure functions, limited scope, etc. — makes it easier to hold a system in my head. Trying to understand code written by other people (or one’s past self) is hard enough, so if I’m going to have any chance of understanding, shaping, and directing code written by a machine, I’ll take all of the invariants I can get =D
If you have any favorite approaches for building this kind of stuff — Linux sandbox APIs, version control hooks, build-your-own-harness libraries, etc. — or if you’re interested in exploring/collaborating in this space, please let me know!
Misc. stuff
Deterministic workflows for LLMs aren’t just about the code itself — my friend Colin built the specific workflow he wanted using the Pi coding agent:
The core idea is: instead of asking an agent to “go build this”, the extension drives it through a structured lifecycle: refine, plan, review the plan, implement, review, fix findings, manual test, commit, and merge.
Agents tend to get distracted by spurious context, influenced by context earlier in the conversation, etc. The extension uses Pi’s conversation tree to give each workflow step an isolated context.
Buttery Smooth Emacs: This flickering is a predictable consequence of the “do what the fuck I want when I want it” redisplay strategy Emacs uses. There’s no coordination between your video card, your GUI system, Emacs, and your sinful soul.
The Mystery in the Medicine Cabinet: Acetaminophen, ibuprofen, and what doctors probably want you to know.
“Value capture occurs when an agent’s values are rich and subtle; they enter a social environment that presents simplified - typically quantified — versions of those values; and those simplified articulations come to dominate their practical reasoning.”
AI & Software Quality with Shawn Wang (aka swyx). “To succeed in technology and AI you need to have a sincere yearning for science fiction. If you don’t fundamentally believe or want to achieve science fiction and make the thing that you saw on TV, the thing that you talk about at late night or on podcasts, you don’t fundamentally want to make that real, then you’re just criticizing things as like "oh well, yeah, everything is hard and we’re not there yet and we’ll never be”, then you’re not going to be part of that conversation because you’re not trying to be. And it’s really difficult to embrace because I haven’t been that, right?“
Heterofriendly: The Intuition for Why You Always Need Robust Standard Errors – Data Colada
RE#: how we built the world’s fastest regex engine in F#. "intersection and complement are genuinely useful operators that have been missing from regex engines for far too long. being able to describe what you want as a combination of properties, rather than cramming everything into one monolithic pattern, is a much more natural way to think about matching. and now you can do it with linear-time guarantees.”